Understanding these foundational concepts will help you make the most of Lume’s capabilities. This guide introduces the key components and how they work together.
Project Basics
Source Data
The input data you want to transform
Target Schema
The desired structure for your output data
Source Data
Source data is any user-provided data that you want to interpret or transform. Lume currently supports CSV files, and you can upload multiple CSV files to work with. All data must be structured, meaning:- The first row must contain column headers/names
- Each subsequent row must follow the same structure
- Data should be organized in a tabular format
- Each column should contain consistent data types
- Source Data: Your primary customer or business data that needs to be transformed
- Seed Data: External or internal enhancement data that can be used to enrich your source data. This includes:
- Reference data (e.g., country codes, state abbreviations)
- Lookup tables
- Master data
- Any non-customer data that helps enhance your primary dataset
While Lume only requires a single record to generate mapping logic, providing larger data samples improves mapping accuracy through better pattern recognition.
Support for JSON and XML formats is coming soon! In the meantime, we recommend converting these files to CSV or reaching out to our support team for assistance.Need support for additional data formats? Contact the Lume team for assistance.
Example Source Data
Example Source Data
Target Schema
A target schema defines the desired output format for your transformed data. It uses YAML format to specify:- Target Model Name
- Column Names
- Test Rules
- Business logic and descriptons
Example Target Schema
Example Target Schema
Key Components
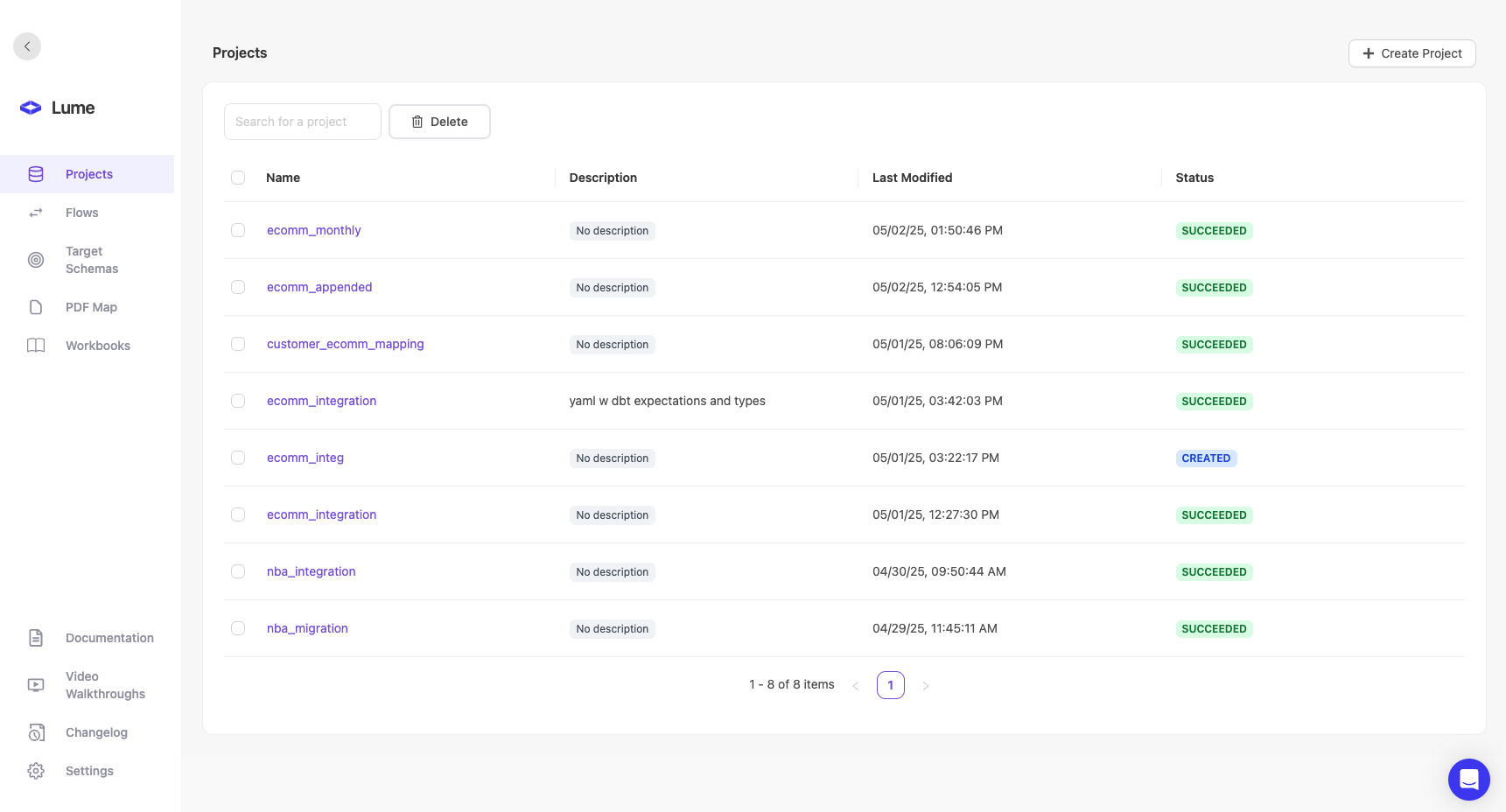
Projects
Orchestrate your data transformation journey
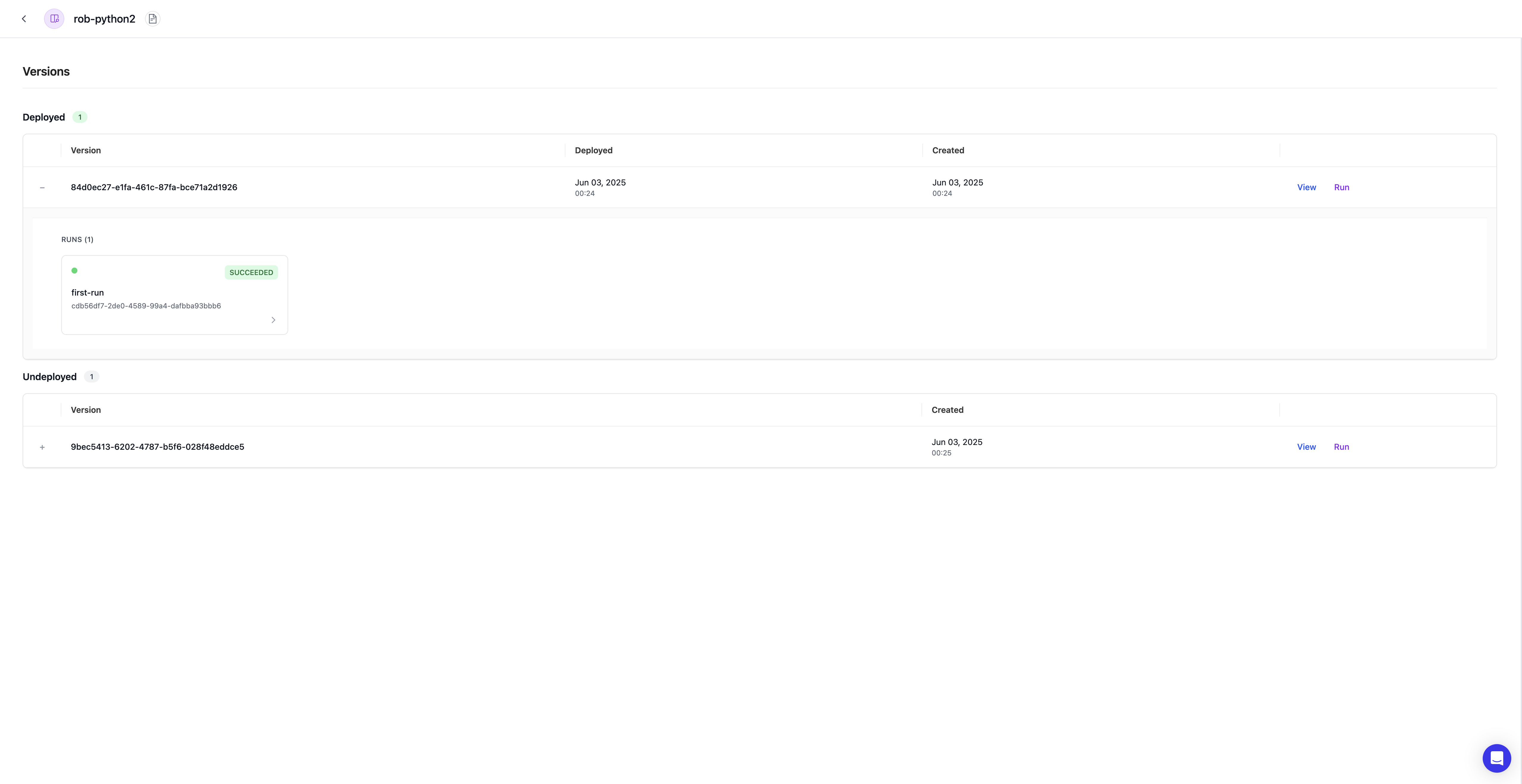
Project Versions
Manage versions of a Project
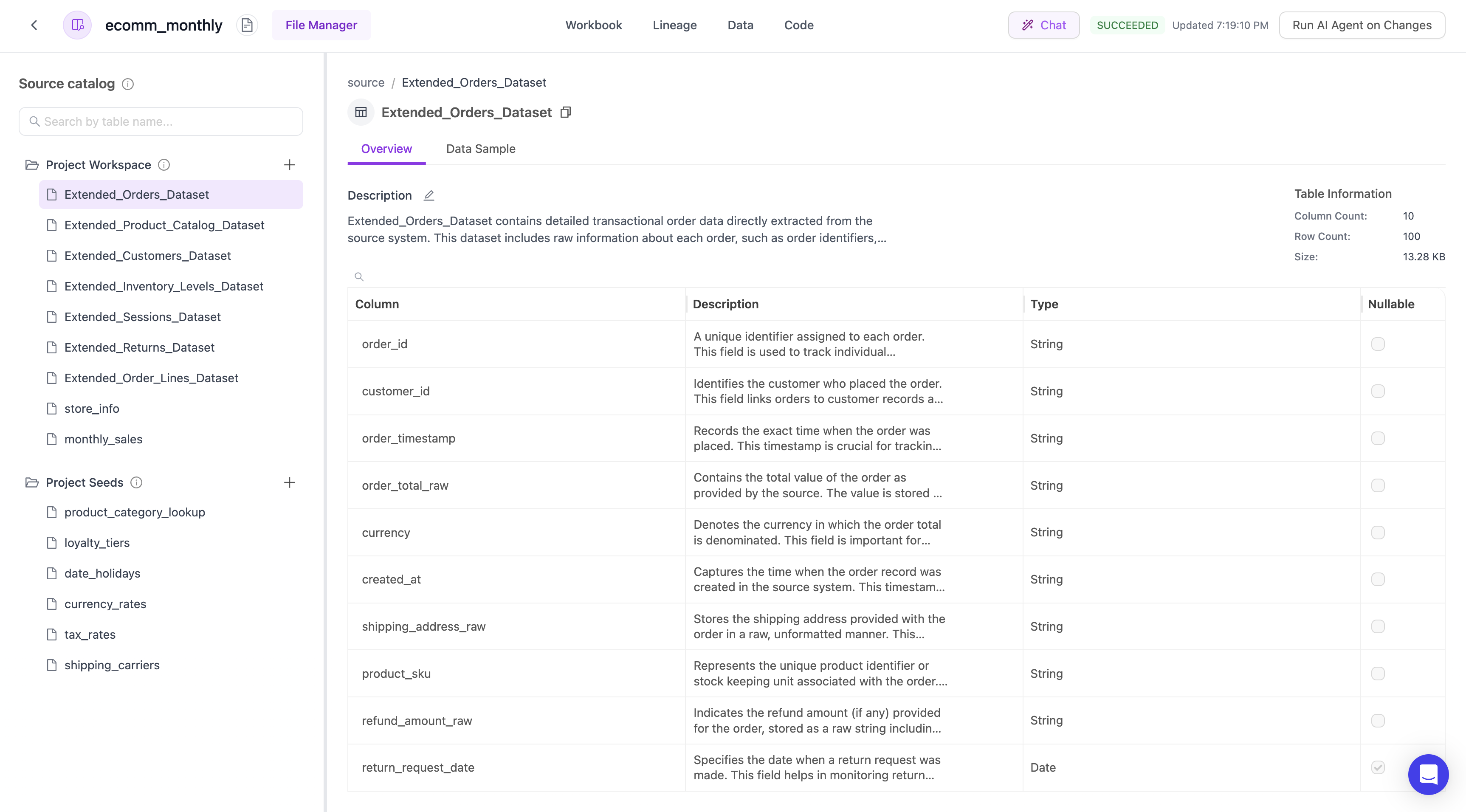
File Manager
Manage files for a given project
Workbook
AI-powered data transformation
Code
Execute and monitor your transformations
Lineage
Track table and column lineage
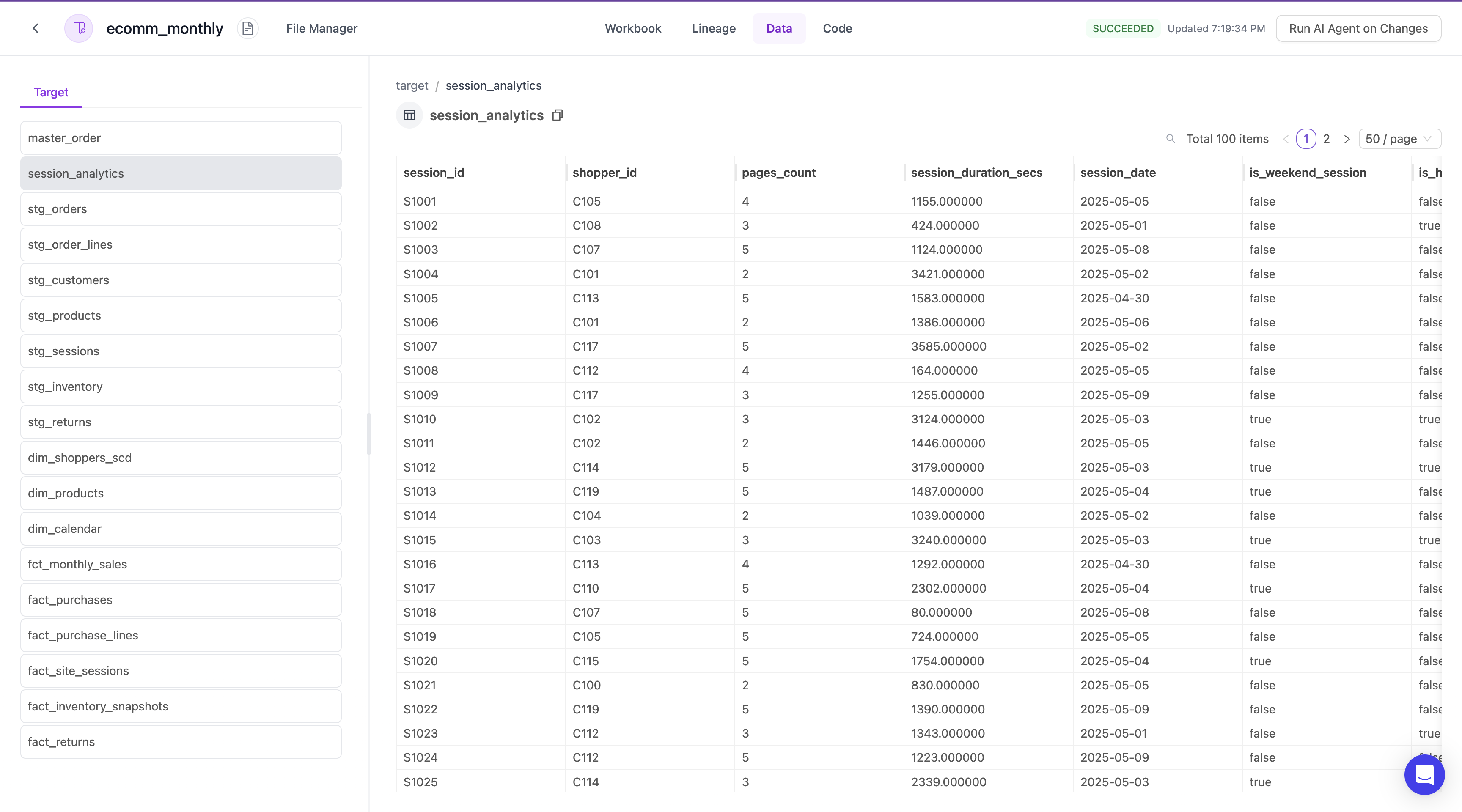
Data
Easily view the transformed data
Projects
A Project is your complete data transformation pipeline. It can:- Accept multiple file inputs (sources and seeds)
- Include multiple transformation steps
- Join and combine data
- Produce final mapped output
Project Versions
The project versions is a place to quickly manage different versions of your project and the runs associated with each version. Lume will automatically snapshot versions of the project as edits are made that result in changes to the code. These changes include:- Code
- Source Schema
- Target Schema
File Manager
The file manager is a place to manage and access your uploaded data. It can:- View metadata per model on row count, column count, and file size.
- Insert, upsert, and remove source tables and source seed files.
- Add additional context to the source table description to guide the AI generation.
- Provide column level metadata around data type, nullability, and additional notes.
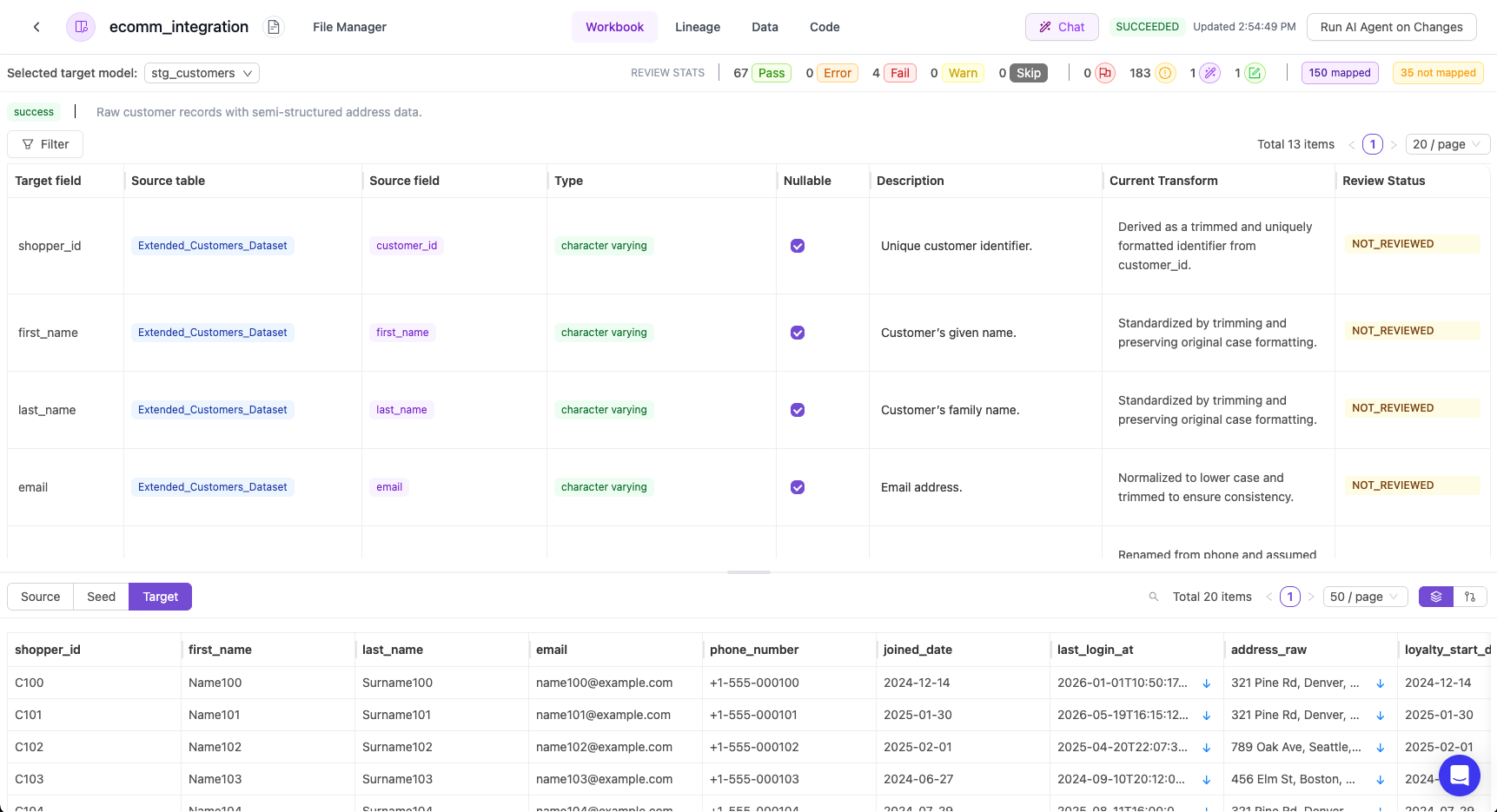
Workbook
Lume generates a spreadsheet style artifact called a Workbook, but you don’t need to be a programmer to use it effectively. The platform provides: Core Concepts:- Data lineage showing how fields map between source and target
- Sample data previews for curosry visual inspections
- Natural language explanations of the transformation logic
- Interactive edit interface for adjusting or providing additional mapping context
- AI Chat to explore daata nd gain a deeper understanding
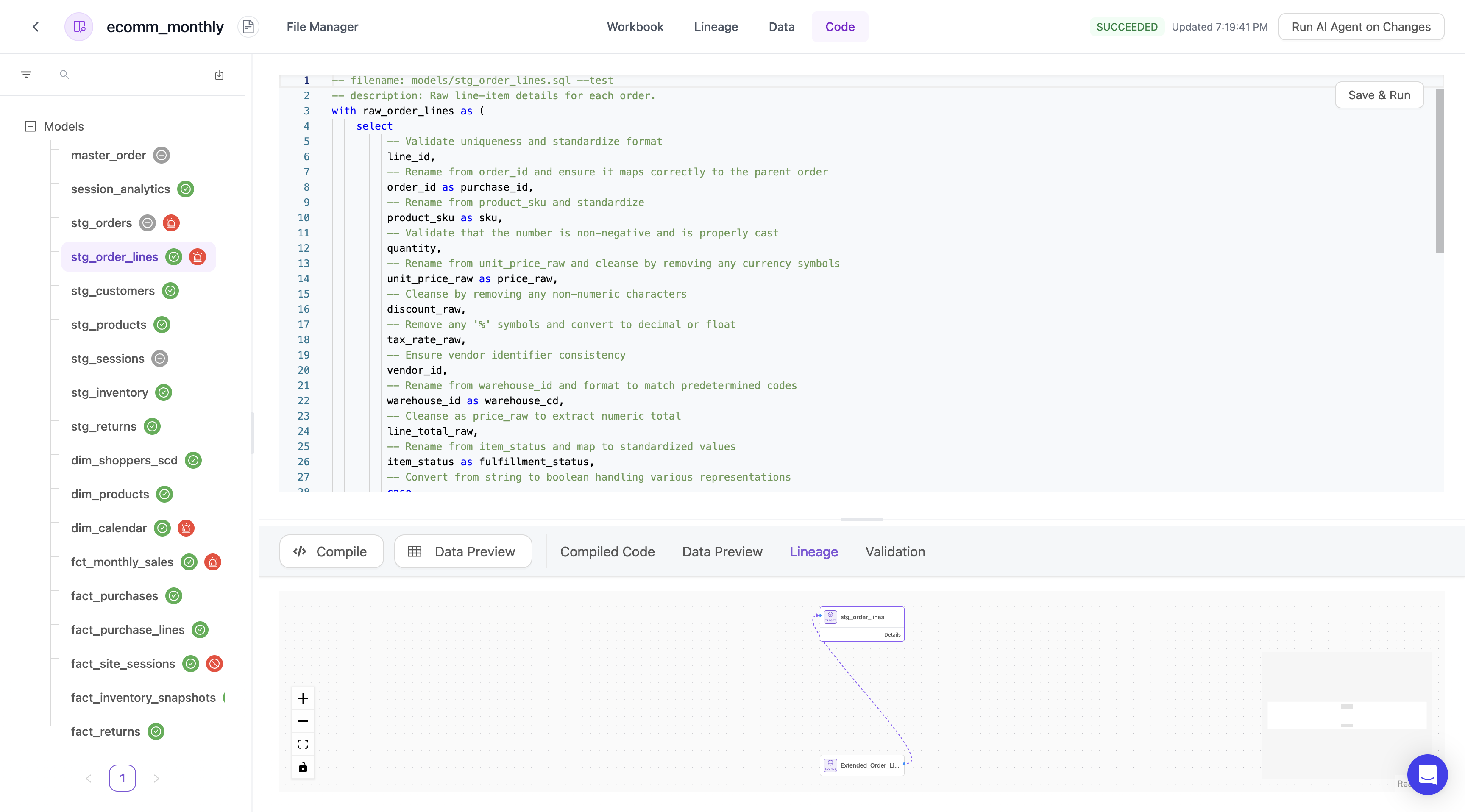
Code
Code represents the section to gain insights about the testing validation and sql models produced:- Compiled Code
- Data Preview
- Lineage
- Validation
Lineage
A visual representation of the table and column level lineage to better understand the relationships between the transformations that Lume’s AI engine created.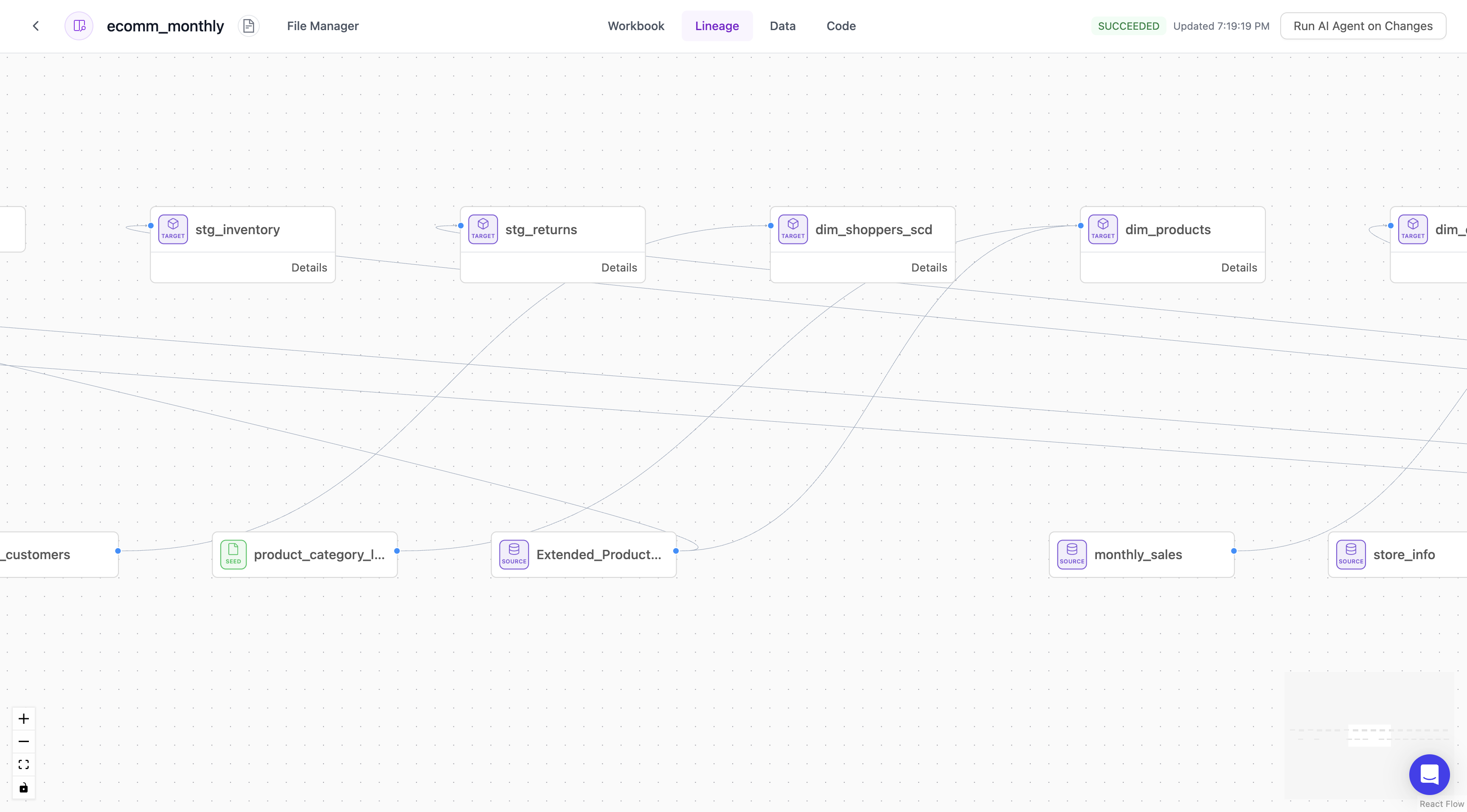
Data
Lume provides comprehensive target data review. You can quickly scan the set of produced data to ensure it passes a quick visual inspection.